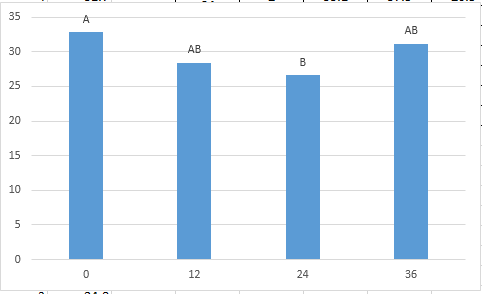
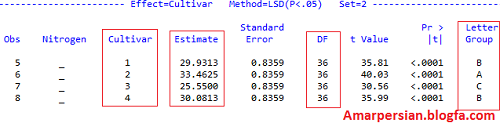
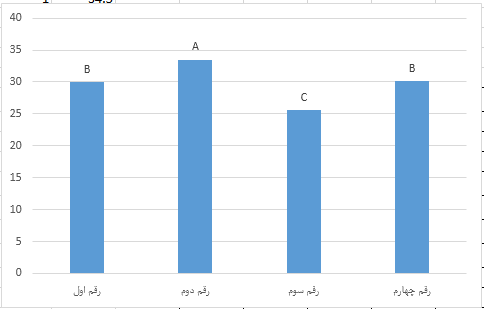
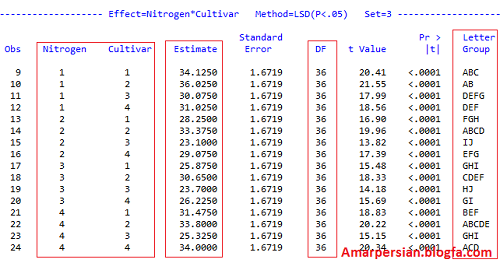
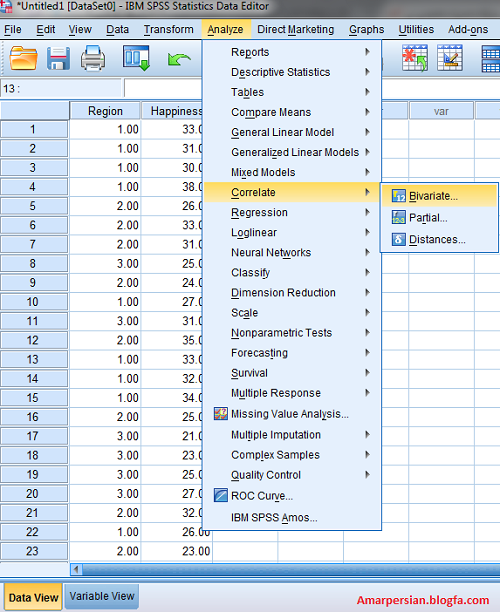
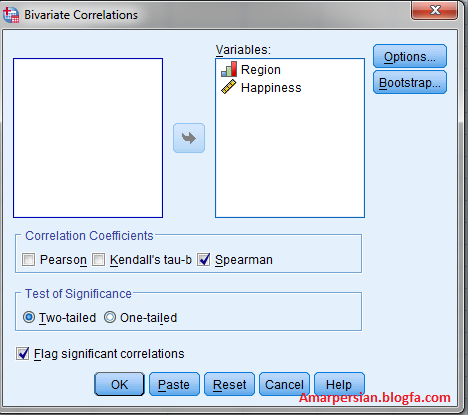
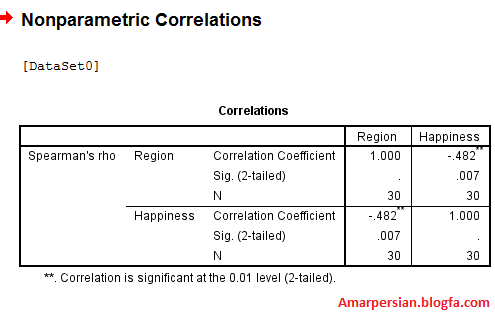
REGRESSION
رگرسیون و انواع آن
مقدمه
در این درس انواع آزمون های رگرسیونی پرکاربرد مورد بررسی قرار گرفته
است. فیلم این درس با استفاده از نرم افزار SPSS مفاهیم را به نمایش
میگذارد.
هدف تحلیل رگرسیونی
تحلیل رگرسیونی (یا تحلیل وایازش) فن و تکنیکی آماری برای بررسی و مدل
سازی ارتباط بین متغیر وابسته و متغیر مستقل بوده و هدف آن پیشبینی
متغیر وابسته از روی متغیر و یا متغیرهای مستقل میباشد . مهمترین تفاوت
رگرسیون و هم بستگی در این است که رگرسیون ماهیت پیشبینی میزان متغیر
وابسته از روی مدلی که متغیر مستقل یکی از مولفههای آن است را دارد. در
حالی که هم بستگی صرفا نشاندهنده شدت رابطه متغیر (متغیرهای) مستقل و
وابسته میباشد.
- پیشفرضهای مدلهای رگرسیون
- وجود مدل نظری که احتمال وجود رابطه بین متغیرها و مدل را بالا ببرد
- نرمالبودن توزیع
- مساوی بودن واریانس ها بین سطوح متغیر وابسته و مستقل
- باید بین متغیر وابسته و مستقل مرزی وجود داشته باشد، از دو مشخصه جدا
باشند.. به بیان بهتر، نباید اشتراکی بین متغیر مستقل و وابسته وجود داشته
باشد
- انواع تحلیل مبتنی بر رگرسیون
در مطالعه روش های تحلیل رگرسیون 6 دسته مهم قابل ذکر هستند.
- رگرسیون خطی ساده و رگرسیون خطی چند گانه
- رگرسیون لجستیک دوگانه و رگرسیون لجستیک چندگانه
- رگرسیون به روش تخمین منحنی
- رگرسیون رتبهای
- رگرسیون پروبیت
. رگرسیون خطی ساده و رگرسیون خطی چند گانه (Simple&Multiple leanear regression)
رگرسیون ساده خطی یک ابزار آماری است که در آن به بررسی رابطه یک متغیر
مستقل (پیش بین) و یک متغیر وابسته پرداخته میشود. حال اگر تعداد
متغیرهای مستقل در این رابطه خطی بیش از یک عدد شود، مدل رگرسیون، خطی
چندگانه نامیده میشود. معادله رگرسیون خطی ساده به شکل Y=AX+B و
رگرسیون خطی چند گانه به صورت Y = a + b1X1 + b2X2 + … + bnXnمیباشد.
. رگرسیون لجستیک دوگانه و رگرسیون لجستیک چندگانه
رگرسیون لوجستیک، هم چون رگرسیون خطی میباشد با این تفاوت که در این
نوع پیشبینی، نتیجه نهایی در مورد سطح یا سطوح متغیر وابسته دو جوابی
میباشد. به عبارت دیگر، در این رگرسیون متغیرهای مستقل در قالب مدلی
ارائه میشوند و سعی در پیشبینی متغیر وابسته و یا سطوح آن در قالب یک
حالتی از آری یا نه به عمل میآید.
رگرسیون لجستیک دوگانه به حالتی اطلاق میشود که متغیر وابسته یک سطح
دارد. مثلا این که ببینیم چه مشخصههایی از زندگی موجب ایجاد سکته قلبی می
شود. در اینجا سکته قلبی متغیر وابسته میباشد.
رگرسیون لجستیک چندگانه به وضعیتی گفته میشود که متغیر وابسته بیش از
یک سطح دارد. برای نمونه اگر بخواهیم ببینیم که چه عواملی موجب میشود که
مخاطبان کدام یک از شبکههای یک یا دو یا سه را برای دیدن انتخاب کنند، از
رگرسیون لجستیک چندگانه سود میبریم. در این مثال، عوامل مختلف به عنوان
متغیر مستقل و انتخاب شبکه به عنوان متغیر وابسته شناخته میشود. این
متغیر وابسته سه سطح دارد که پاسخ آن آری یا خیر است (استفاده از شبکه 1،
استفاده از مطالب شبکه 2، استفاده از محصولات رسانهای شبکه 3).
به طور کلی معادله رگرسیون لجستیک به شکل زیر میباشد

در این مدل، p احتمال این است که جواب ما به سوال دوگانه آری شود. هر چه
این احتمال به یک نزدیک شود، احتمال تحقق ویژگی در مورد سطح یا سطوح متغیر
وابسته بالاتر میرود.
2-3. رگرسیون به روش تخمین منحنی(Curve Estimation)
با استفاده از این قابلیت دادهها و نمودارهای مرتبط با آنان با استفاده
از 11 مدل آزمون میشوند. همانند دیگر تحلیلهای رگرسیونی، قبل از انجام
این تحلیل میباید در مورد دادههای پژوهش و این که به چه مدلی نزدیکتر
میباشند، شناخت اولیه داشته باشد
رگرسیون خطی Linear. Y = b0 + (b1 * t).
رگرسیون لگاریتمی Logarithmic Y = b0 + (b1 * ln(t)).
رگرسیون معکوس. Inverse Y = b0 + (b1 / t).
رگرسیون درجه 2. Quadratic Y = b0 + (b1 * t) + (b2 * t**2).
رگرسیون درجه 3 Cubic Y = b0 + (b1 * t) + (b2 * t**2) + (b3 * t**3).
رگرسیون پاورPower. Model whose equation is Y = b0 * (t**b1) or ln(Y) = ln(b0) + (b1 * ln(t)).
رگرسیون مرکبCompound. Model whose equation is Y = b0 * (b1**t) or ln(Y) = ln(b0) + (ln(b1) * t).
منحنی کروS-curve. Model whose equation is Y = e**(b0 + (b1/t)) or ln(Y) = b0 + (b1/t).
رگسیون لجستیک Logistic Y = 1 / (1/u + (b0 * (b1**t))) or ln(1/y-1/u) = ln (b0) + (ln(b1) * t)
رگرسیون رشد Growth Y = e**(b0 + (b1 * t)) or ln(Y) = b0 + (b1 * t).
رگرسیون نمایی Exponential Y = b0 * (e**(b1
2-4. رگرسیون رتبهای
در رگرسیون رتبهای اثر متغیر و یا متغیرهای مستقل بر روی متغیر
وابستهای که سطوح مختلف و رتبه ای دارد، پیشبینی میشود. برای مثال فرض
کنید اثر سه نوع افزودنی خوراکی بر روی دیدگاه مشتریان در مورد طعم یک نوع
کیک میتواند با استفاده از این نوع تحلیل رگرسیون تست شود. توجه داشته
باشید که در این مثال زمانی میتوانید از رگرسیون رتبه ایس استفاده کنید که
طعم کیک را به صورت رتبهای طبقهبندی کرده باشید (برای نمونه از طعم خیلی
بد تا طعم خیلی خوب).
2-5. رگرسیون پروبیت (تحلیل پروبیت-Probit analysis)
هنگامی که خروجی (متغیر وابسته) دو حالت داشته باشد (آری یا خیر) و هدف
بررسی شدت متغیر مستقل در پیشبینی این دو حالت باشد، از تحلیل پروبیت
استفاده می شود. برای نمونه فرض کنید که میخواهید قدرت کشندگی یک نوع حشره
کش را به روش تحلیل پروبینت اندازهاگیری کنید. در این مثال سطوح مختلف
متغیر مستقل (غلظت حشرهکش در محیطهای مختلف) و تعداد حشرههای کشته شده
(متغیر وابسته) میباشند.
3. ملاحظات انتخاب مدل در رگرسیون چند گانه
در رگرسیون چندگانه ، چند متغیر مستقل مدلی را میسازند که مقدار متغیر
وابسته را پیشبینی میکنند. از آن جا که امکان دارد این متغیرهای مستقل با
یکدیگر رابطه داشته باشند، همیشه این نگرانی وجود دارد که آیا مدل به دست
آمده اعتبار دارد یا خیر. برای نمونه فرض کنید در یک مدل رگرسیون، سه متغیر
وجود دارند. ممکن است تک تک متغیرهای مستقل با متغیر وابسته رابطه مثبتی
داشته باشند ولی زمانی که این متغیرها با هم وارد مدل رگرسیون می شوند این
امکان وجود دارد که به دلیل وجود رابطه بین متغیرهای مستقل، ضریب رگرسیون
یک یا دو متغیر منفی محاسبه گردد و یا امکان دارد ضرایب رگرسیون اصلا معنی
دار نشوند. اگر چه امکان دارد که در دنیای واقع، این مدل درست باشد ولی
این نگرانی وجود دارد که ممکن است نتیجه برعکس بوده و ناشی از اشتباه در
تحلیل آماری رقم خورده باشد. برای حل این مشکل، روشهایی برای وارد نمودن
متغیرهای مستقل درون مدل رگرسیون ابداع شده اند:
- انتخاب رو به جلو (Forward Selection) در این روش به ترتیب تک تک
متغیرهای مستقل وارد مدل رگرسیون می شوند و در هنگان اضافه شدن، یک معیار
برای پذیرش متغیر مستقل در نظر گرفته میشود. - حذف پسرو (Backward Elimination) در این روش به صورت رندم و ابتکاری
همه متغیرهای مستقل وارد مدل میشوند و به صورت مرحله به مرحله از یک نوع
معیار خاص برای حذف هر کدام از متغیرها بهره جسته میشود. در صورتی که با
توجه به معیار مورد نظر وجود متغیر غیر ضروری باشد، آن متغیر از مدل حذف
میشود.. - نشانگر گام به گام (Stepwise Entry) در این روش هم چون انتخاب رو به
جلو متغیرها تک تک اضافه می شوند با این تفاوت که بعد از اضافه شدن، تک تک
متغیرها بر اساس معیار روش حذف پس رو بررسی میشوند.
شایان توجه است که در نرم افزار spss متدها به شیوه زیر ارائه گشتهاند:
- روش Enter (ورود): بدون هیچ قاعده تمام متغیرها وارد شوند.
- روش Stepwise (گام به گام) همان روش حذف پسرو می باشد
- روش Remove (خروج) در این روش یک متغیر حذف موقت شده و مدل رگرسیون
دوباره و بدون حضور متغیر حذف شده تست می شود اگر نتایج بهتر باشد متغیر
حذف نهایی می شود. - روش Backward (پسرو) همان روش نشانگر گام به گام است.
- روش Forward (پيشرو) همان روش انتخاب رو به جلو است.